Beyond Creation: Harnessing RAG for Video Content Distribution and Monitoring

In the fast-paced world of digital media, creating high-quality video content has become increasingly vital. Yet, many enterprises overlook a critical factor—effective distribution and discoverability. Although platforms like YouTube, Instagram, and TikTok have revolutionized content dissemination for public use, very few solutions are providing a integrated approach to enterprise content. Indeed, traditional text-based search methods fail to meet user expectations for pinpointing exact video segments or topics, especially within extensive video libraries. This gap underscores the need for new search methods such as integrating Retrieval-Augmented Generation (RAG) into enterprise strategies. It can significantly enhance how video content is distributed, discovered, and become a critical component that enterprise have to monitor.
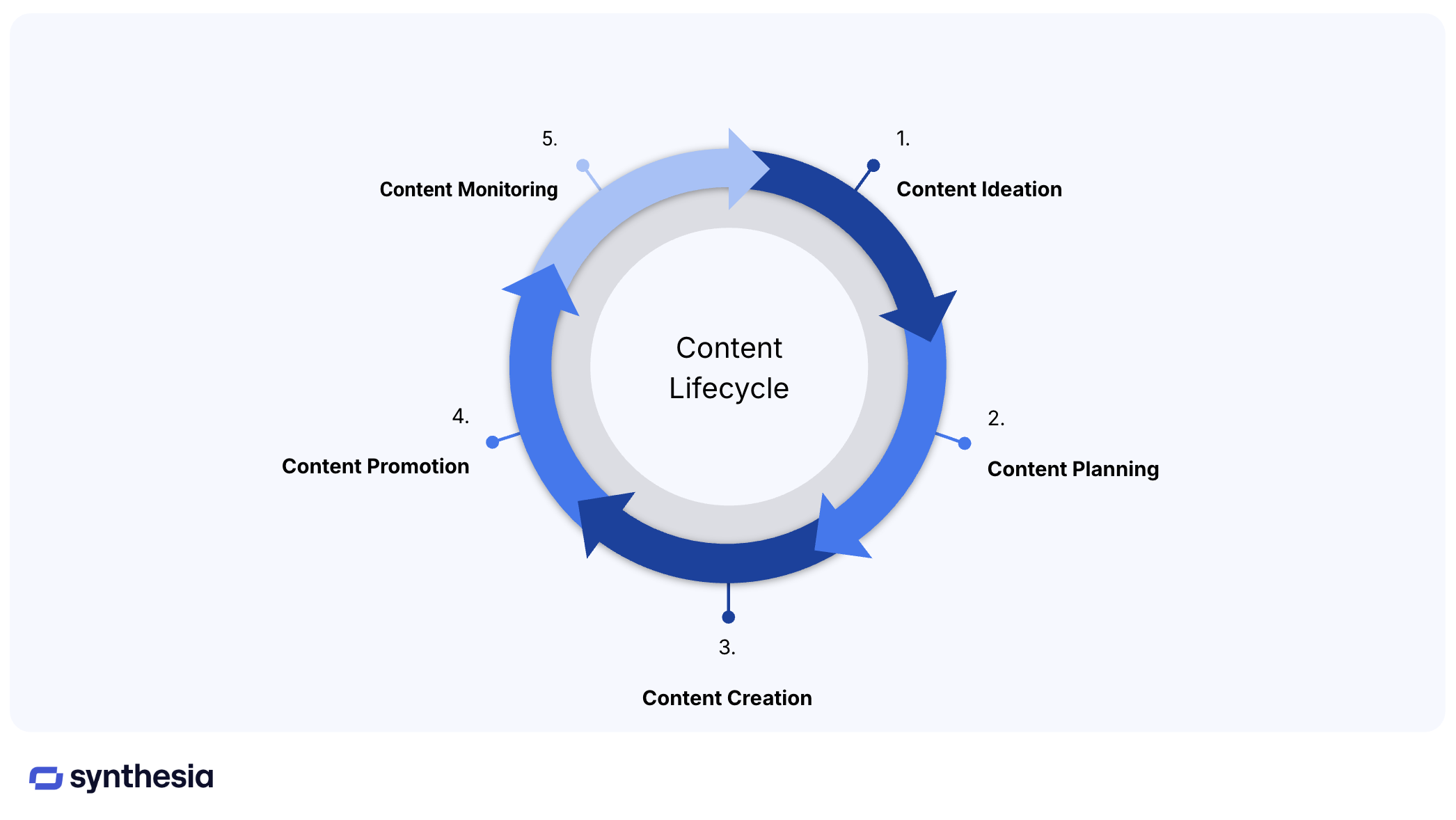
In this article, we will leverage RAG alongside Large Language Models (LLMs) to provide a robust solution, empowering users to access relevant video content quickly, accurately and reliably and offer one solution for Content Promotion.
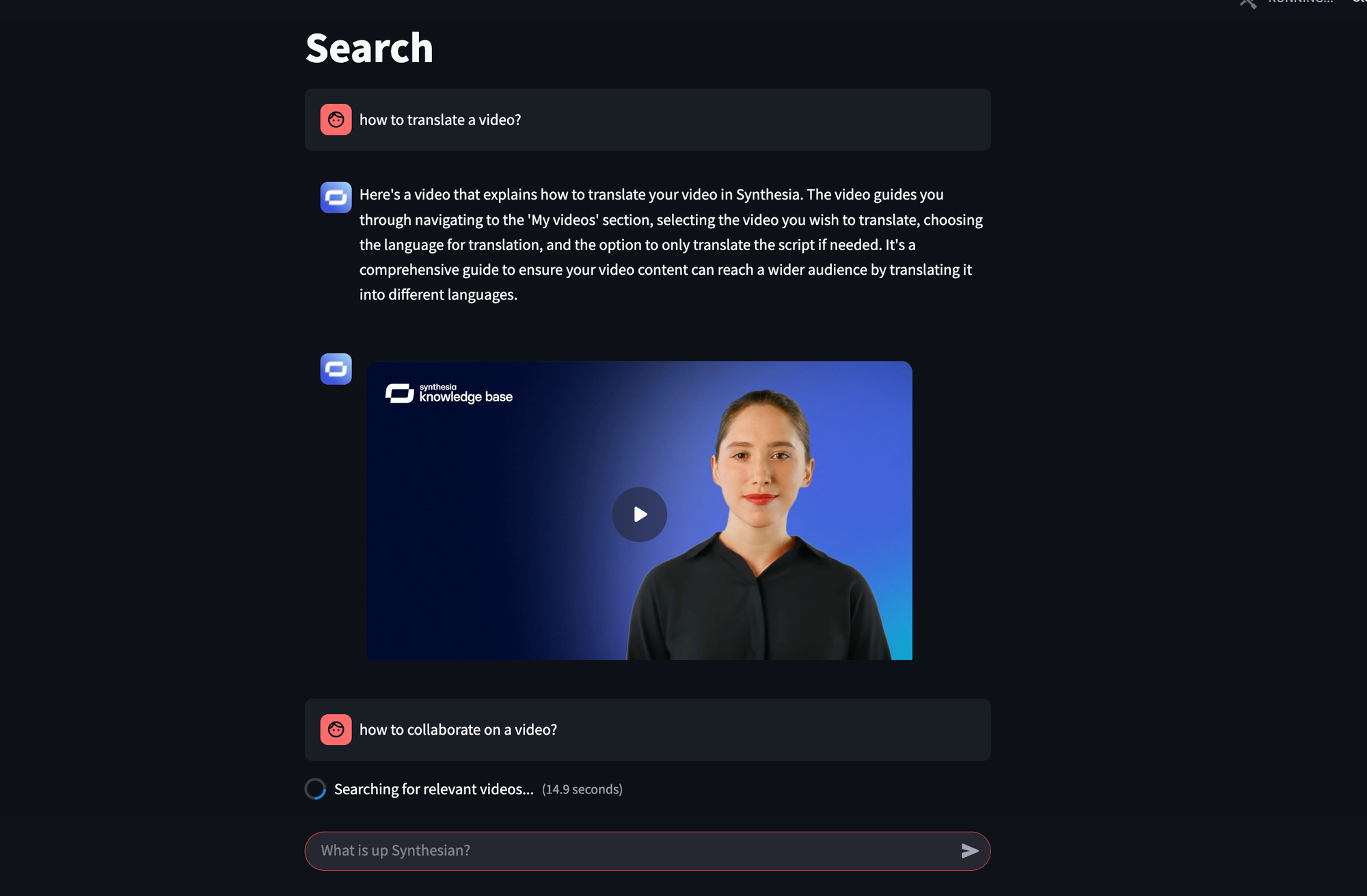
Understanding RAG in the Context of Video Content
Retrieval-Augmented Generation (RAG) combines the power of retrieval systems and generative LLMs to dynamically source and generate content based on user queries. At its core, RAG retrieves contextually relevant information, augmenting LLM-generated responses to ensure accuracy and context-awareness.
RAG leverages advanced embedding techniques and vector databases—like MongoDB Vector Search—to store and retrieve highly specific segments from extensive video content libraries. By converting video content into embeddings, each segment becomes searchable beyond simple keywords, enhancing precision.
No need to add keywords, iterate over multiple titles, the RAG model with LLM understand the meaning of the query and the content of the video to find accurate matching.
A practical example would be an enterprise FAQ platform that employs RAG. Users ask questions via chatbots; the RAG system retrieves relevant video segments that precisely answer their inquiries, improving engagement and significantly reducing support tickets. Imagine all HR content could be made searchable to find videos about sickness policy, promotion cycles, and more all in a single place.
Why Distribution is as Crucial as Creation
Enterprises often invest heavily in producing high-quality videos. This is for instance where Synthesia shines where high quality video can easily be created and maintained.
Yet, enterprises neglect the strategic distribution essential for maximizing reach and ROI. This oversight can lead to underutilized content, and decreased returns on investment. Poorly distributed content often gets missed across all the rest of the content which ultimately miss the ability to achieve its intended impact.
Effective distribution across prominent enterprise platforms—Slack or Teams, Sharepoint, FAQ pages—is vital. Each platform serves unique purposes and user demographics, collectively amplifying visibility and enhancing user interaction. In a nutshell, distribute where people are.
Strategically managed distribution significantly elevates content value, driving stronger business outcomes through increased user engagement, brand authority, and more effective knowledge dissemination.

Implementing RAG for Video Content
Successfully implementing RAG in your video content strategy involves a few essential steps:
1. Creating Embeddings
- Convert videos to text using automatic speech recognition (ASR) or with Synthesia, download the captions from your videos via API.
- Generate embeddings from textual data for vector-based searches.
Curl command to fetch the metadata of a video including the link to the srt file. https://docs.synthesia.io/reference/retrieve-a-video
curl --request GET \
--url https://api.synthesia.io/v2/videos/<your_video_id> \
--header 'Authorization: <your_key>' \
--header 'accept: application/json'2. Vector Search with MongoDB:
- Utilize MongoDB Vector Search to index and quickly retrieve embeddings matching user queries.
Below is an example of a setup with Langchain to create a vector search and query it.
self.vectorstore = MongoDBAtlasVectorSearch(
collection=MongoClient(mongodb_uri)[db_name][collection_name],
embedding=self.embeddings,
index_name=index_name,
relevance_score_fn="cosine",
)
vectorsearch_results = self.vectorstore.similarity_search_with_score(
"how to share a video in synthesia?", k=10
)
print("vectorsearch_results", vectorsearch_results)
for res, score in vectorsearch_results:
print(f"* [SIM={score:3f}] {res.page_content} [{res.metadata}]")3. Leveraging MultiQueryRetriever:
- This retriever enhances search accuracy by generating multiple queries from a single user input, improving relevance and recall rates.
self.multi_retriever = MultiQueryRetriever.from_llm(
retriever=self.base_retriever,
llm=ChatOpenAI(temperature=0)
)4. Contextual Compression and CohereRerank:
- Apply contextual compression to filter irrelevant results, ensuring only pertinent segments are delivered.
- CohereRerank further prioritizes search results based on contextual relevance and intent matching.
self.compressor = CohereRerank(
model="rerank-english-v2.0",
top_n=4
)
self.final_retriever = ContextualCompressionRetriever(
base_compressor=self.compressor,
base_retriever=self.multi_retriever
)Bring it all together
import os
from typing import List, Dict, Any, Optional
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain.tools import BaseTool
from pydantic import BaseModel, Field
from pymongo import MongoClient
from langchain_openai import OpenAIEmbeddings
from langchain.retrievers.multi_query import MultiQueryRetriever
from langchain_mongodb import MongoDBAtlasVectorSearch
from langchain.retrievers import ContextualCompressionRetriever
from langchain_cohere import CohereRerank
load_dotenv()
class VideoSearchInput(BaseModel):
query: str = Field(..., description="The search query to find relevant videos")
class VideoSearchTool(BaseTool):
name: str = "synthesia_video_search"
description: str = "Search for knowledge videos about Synthesia. Returns a list of videos with their rerankSearchScore. The link to the video is https://share.synthesia.io/<video_id>"
args_schema: type[BaseModel] = VideoSearchInput
embeddings: Optional[OpenAIEmbeddings] = None
vectorstore: Optional[MongoDBAtlasVectorSearch] = None
base_retriever: Optional[Any] = None
multi_retriever: Optional[Any] = None
compressor: Optional[CohereRerank] = None
final_retriever: Optional[Any] = None
def __init__(self):
"""Initialize the tool with vector store and retrievers."""
super().__init__()
# Initialize embeddings
self.embeddings = OpenAIEmbeddings(
model="text-embedding-ada-002"
)
# Initialize MongoDB Vector Store
mongodb_uri = os.getenv('MONGODB_URI')
db_name = os.getenv('MONGODB_DB_NAME')
collection_name = os.getenv('MONGODB_COLLECTION_NAME')
index_name = os.getenv('MONGODB_INDEX_NAME')
self.vectorstore = MongoDBAtlasVectorSearch(
collection=MongoClient(mongodb_uri)[db_name][collection_name],
embedding=self.embeddings,
index_name=index_name,
relevance_score_fn="cosine",
)
# Create base retriever
self.base_retriever = self.vectorstore.as_retriever(
search_type="similarity",
search_kwargs={"k": 10}
)
# Create multi-query retriever for better recall
self.multi_retriever = MultiQueryRetriever.from_llm(
retriever=self.base_retriever,
llm=ChatOpenAI(temperature=0)
)
# Initialize Cohere reranker
self.compressor = CohereRerank(
model="rerank-english-v2.0",
# model="'rerank-v3.5'" # Video Search
top_n=4
)
# Create the final retriever with reranking
self.final_retriever = ContextualCompressionRetriever(
base_compressor=self.compressor,
base_retriever=self.multi_retriever
)
def _run(self, query: str) -> Dict[str, Any]:
"""Run the video search tool with vector search and reranking."""
results_list = self.final_retriever.invoke(query)
# Format final results
final_results = []
for doc in results_list:
metadata = doc.metadata.get("metadata", {})
final_results.append({
"pageContent": doc.page_content,
"metadata": {
"videoID": metadata.get("videoID", ""),
"title": metadata.get("title", ""),
"thumbnail_gif": metadata.get("thumbnail", {}).get("gif", ""),
"thumbnail_image": metadata.get("thumbnail", {}).get("image", ""),
},
"relevance_score": doc.metadata.get("relevance_score", 0.0)
})
return {"data": final_results}
def _arun(self, query: str) -> Dict[str, Any]:
"""Async run the video search tool."""
raise NotImplementedError("Async not implemented")Integrating Datadog for Advanced Monitoring and Reliability
Monitoring content performance and retrieval efficiency is crucial for ongoing optimization but also to ensure reliability of the system. Datadog provides comprehensive analytics tailored explicitly for AI-driven content distribution:
- Performance Metrics: Gain insights into retrieval accuracy, response times, and overall system health.
- User Engagement Analytics: Monitor video interaction metrics to evaluate distribution effectiveness, understanding user preferences and content impact.
- Real-time Issue Detection: Quickly identify and address retrieval inaccuracies or system delays, ensuring consistent reliability and user satisfaction.
With Datadog dashboards, stakeholders can visually monitor essential KPIs, making data-driven decisions to refine and enhance video content strategies continuously.
Setup
The setup process is straightforward, clearly detailed in Datadog’s documentation, and can be implemented quickly—in just a few seconds. See the complete setup guide here: Datadog LLM Observability Setup.
The first step is installing the Datadog SDK. For Python, simply run:
pip install ddtraceIf the Datadog Agent is already running and configured to accept TCP requests for spans on port 8126, you can launch your application using the following command:
DD_SITE=datadoghq.com DD_API_KEY=<your_key> DD_LLMOBS_ENABLED=1 DD_LLMOBS_AGENTLESS_ENABLED=false DD_LLMOBS_ML_APP=video-search DD_TRACE_STARTUP_LOGS=true ddtrace-run python -m streamlit run video_agent_app.pyOnce executed, tracing data will immediately start flowing into Datadog, and traces will become visible in your dashboards. Since this example uses Langchain, traces can sometimes appear fragmented. To ensure all related spans are captured as a single trace, annotate your _run method with the @workflow decorator.
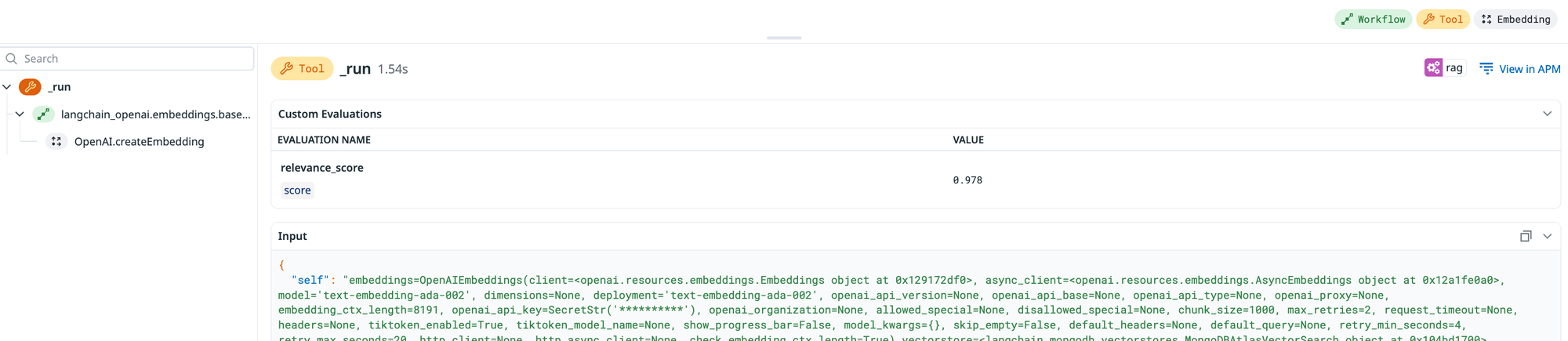
Finally, submit an evaluation to Datadog (as detailed here), leveraging the relevance_score provided by your Retrieval-Augmented Generation (RAG) solution for video content.
Results
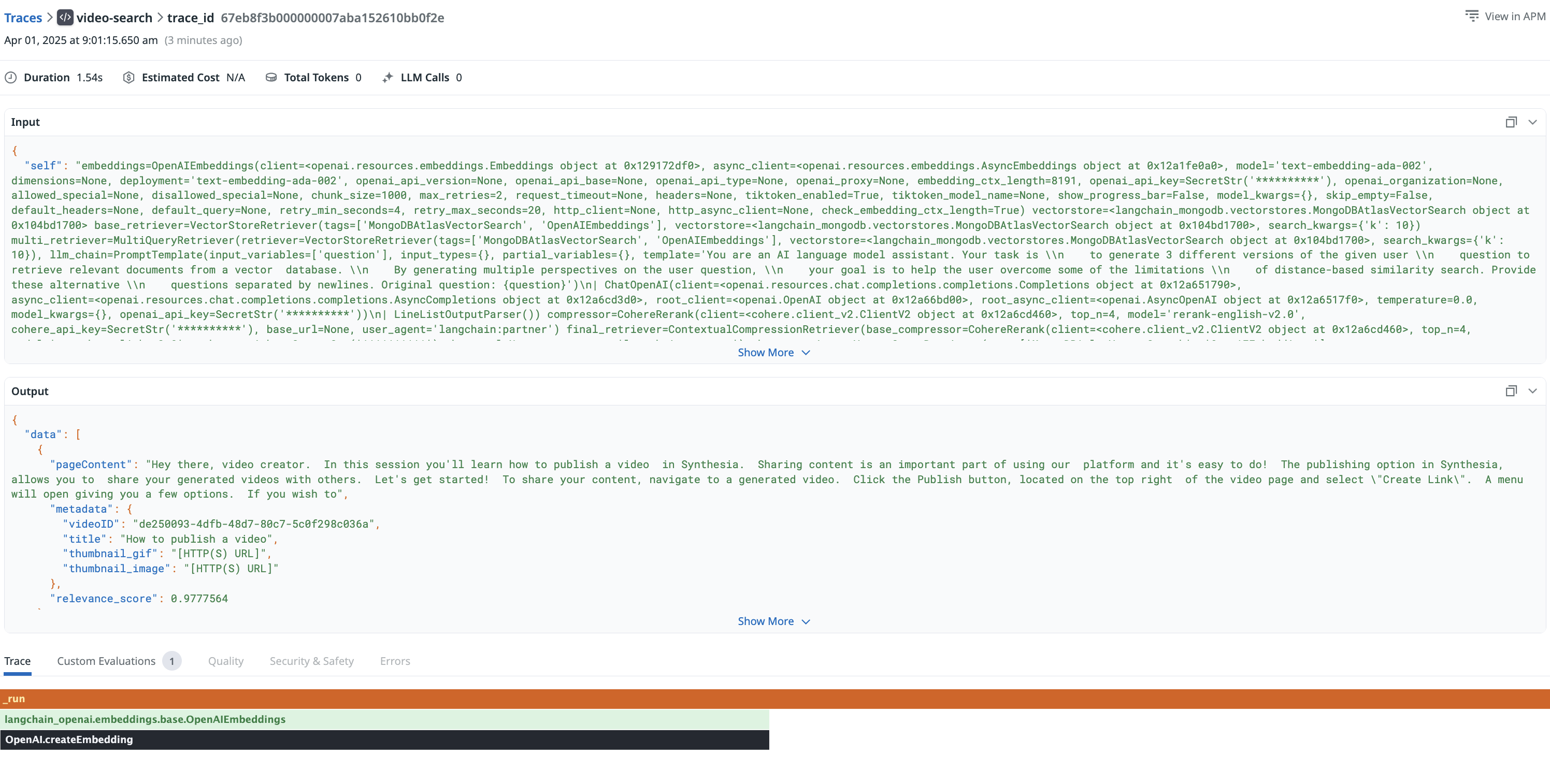
In the Datadog Traces, the complete workflow becomes clearly visible:
- The initial step involves generating embeddings from the user's query.
- Next, a query is sent to the vector database.
- Lastly, the results undergo a reranking operation using Cohere.
This comprehensive view allows us to monitor the entire workflow end-to-end, analyze processing durations, and quickly pinpoint any errors.
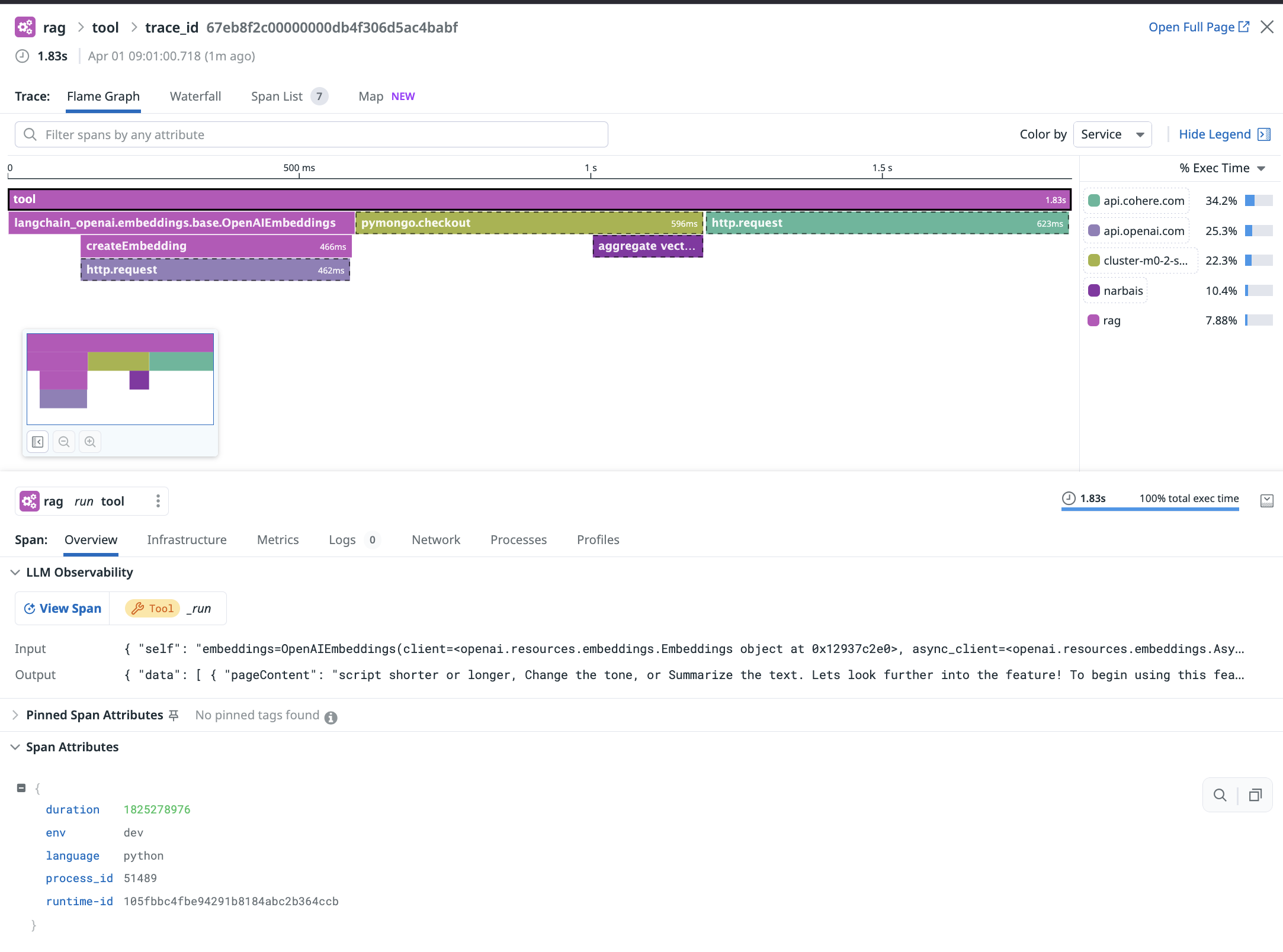
The result from the retrieval workflow is also clearly visible allowing me to troubleshoot if need be and identify the results for each query made by the users.
In addition, since we submitted an evaluation, the relevance_score is not visible in the tool details itself.
Conclusion
While creating outstanding video content is foundational and Synthesia can greatly help for that, strategic distribution and effective monitoring using RAG and Datadog are equally essential. Leveraging RAG's advanced retrieval capabilities transforms video content into highly discoverable, engaging resources, significantly enhancing user interaction and business outcomes. Concurrently, integrating Datadog ensures reliability, allowing organizations to maintain optimal system performance and user satisfaction.
Now is the time for enterprises to audit existing strategies, embracing RAG and Monitoring to achieve superior content distribution, enhanced discoverability, and insightful analytics.
Final code:
import os
from typing import List, Dict, Any, Optional
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain.agents import AgentExecutor, create_openai_functions_agent
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain.tools import BaseTool
from pydantic import BaseModel, Field
from langchain.output_parsers import PydanticOutputParser
import logging
from pymongo import MongoClient
from langchain_openai import OpenAIEmbeddings
from langchain.retrievers.multi_query import MultiQueryRetriever
from langchain_mongodb import MongoDBAtlasVectorSearch
from langchain.retrievers import ContextualCompressionRetriever
from langchain_cohere import CohereRerank
from ddtrace.llmobs.decorators import tool, retrieval
from ddtrace.llmobs import LLMObs
import json
logging.basicConfig()
logging.getLogger("langchain.retrievers.multi_query").setLevel(logging.INFO)
# Load environment variables
load_dotenv()
class VideoSearchInput(BaseModel):
query: str = Field(..., description="The search query to find relevant videos")
class VideoInfo(BaseModel):
videoID: str = Field(..., description="The unique identifier of the video")
thumbnail: str = Field(..., description="The URL of the video thumbnail")
title: str = Field(..., description="The title of the video")
relevance_score: float = Field(..., description="The relevance score of the video")
class VideoResponse(BaseModel):
content: str = Field(..., description="The markdown formatted response content")
videos: List[VideoInfo] = Field(..., description="List of 3 relevant videos with their details")
class VideoSearchTool(BaseTool):
name: str = "synthesia_video_search"
description: str = "Search for knowledge videos about Synthesia. Returns a list of videos with their rerankSearchScore. The link to the video is https://share.synthesia.io/<video_id>"
args_schema: type[BaseModel] = VideoSearchInput
embeddings: Optional[OpenAIEmbeddings] = None
vectorstore: Optional[MongoDBAtlasVectorSearch] = None
base_retriever: Optional[Any] = None
multi_retriever: Optional[Any] = None
compressor: Optional[CohereRerank] = None
final_retriever: Optional[Any] = None
def __init__(self):
"""Initialize the tool with vector store and retrievers."""
super().__init__()
# Initialize embeddings
self.embeddings = OpenAIEmbeddings(
model="text-embedding-ada-002"
)
# Initialize MongoDB Vector Store
mongodb_uri = os.getenv('MONGODB_URI')
db_name = os.getenv('MONGODB_DB_NAME')
collection_name = os.getenv('MONGODB_COLLECTION_NAME')
index_name = os.getenv('MONGODB_INDEX_NAME')
self.vectorstore = MongoDBAtlasVectorSearch(
collection=MongoClient(mongodb_uri)[db_name][collection_name],
embedding=self.embeddings,
index_name=index_name,
relevance_score_fn="cosine",
)
# Create base retriever
self.base_retriever = self.vectorstore.as_retriever(
search_type="similarity",
search_kwargs={"k": 10}
)
# Create multi-query retriever for better recall
self.multi_retriever = MultiQueryRetriever.from_llm(
retriever=self.base_retriever,
llm=ChatOpenAI(temperature=0)
)
# Initialize Cohere reranker
self.compressor = CohereRerank(
model="rerank-english-v2.0",
# model="'rerank-v3.5'" # Video Search
top_n=4
)
# Create the final retriever with reranking
self.final_retriever = ContextualCompressionRetriever(
base_compressor=self.compressor,
# base_retriever=self.multi_retriever
base_retriever=self.base_retriever
)
@tool
def _run(self, query: str) -> Dict[str, Any]:
"""Run the video search tool with vector search and reranking."""
results_list = self.final_retriever.invoke(query)
# Format final results
final_results = []
for doc in results_list:
metadata = doc.metadata.get("metadata", {})
final_results.append({
"pageContent": doc.page_content,
"metadata": {
"videoID": metadata.get("videoID", ""),
"title": metadata.get("title", ""),
"thumbnail_gif": metadata.get("thumbnail", {}).get("gif", ""),
"thumbnail_image": metadata.get("thumbnail", {}).get("image", ""),
},
"relevance_score": doc.metadata.get("relevance_score", 0.0)
})
span_context = LLMObs.export_span(span=None)
LLMObs.submit_evaluation(
span_context,
label="relevance_score",
metric_type="score",
value=final_results[0]["relevance_score"],
)
return {"data": final_results}
def _arun(self, query: str) -> Dict[str, Any]:
"""Async run the video search tool."""
raise NotImplementedError("Async not implemented")
def create_video_agent() -> AgentExecutor:
"""Create and return the video suggestion agent."""
# Initialize the LLM
llm = ChatOpenAI(
api_key=os.getenv('OPENAI_API_KEY'),
model="gpt-4-turbo-preview",
temperature=0
)
# Define the tools
tools = [VideoSearchTool()]
# Create output parser
parser = PydanticOutputParser(pydantic_object=VideoResponse)
print("parser", parser.get_format_instructions())
# Create the prompt
prompt = ChatPromptTemplate.from_messages([
("system", """You are a helpful assistant that suggests relevant videos based on user queries.
When searching for videos:
1. Use the video_search tool to find relevant videos
2. Analyze the results and suggest the most relevant video based on rerankSearchScore
3. If rerankSearchScore is below 0.3, mention that no relevant videos were found
4. If multiple videos are relevant, suggest the first one and then offer additional options
5. Use the information from pageContent to also provide a summary of the video
Your response must be formatted as a JSON object with the following structure:
{format_instructions}
If possible include 3 videos in the `videos` array.
Always provide the video URL in the format: https://share.synthesia.io/<video_id>
"""),
("human", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad"),
]).partial(format_instructions=parser.get_format_instructions())
# Create the agent
agent = create_openai_functions_agent(llm, tools, prompt)
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
verbose=True,
handle_parsing_errors=True
)
return agent_executor
def main():
# Create the agent
agent = create_video_agent()
# Example usage
while True:
user_query = input("\nEnter your query (or 'quit' to exit): ")
if user_query.lower() == 'quit':
break
result = agent.invoke({"input": user_query})
try:
# Parse the output as JSON
response = json.loads(result["output"])
print("\nContent:", response["content"])
print("\nVideos:")
for video in response["videos"]:
print(f"- Video ID: {video['videoID']}")
print(f" Thumbnail: {video['thumbnail']}")
print(f" Relevance Score: {video['relevance_score']}")
except json.JSONDecodeError:
print("\nAgent's response:", result["output"])
if __name__ == "__main__":
main() 


